

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Pierre Colombo, Equall, Paris, France & MICS, CentraleSupelec, Universite Paris-Saclay, France;
(2) Victor Pellegrain, IRT SystemX Saclay, France & France & MICS, CentraleSupelec, Universite Paris-Saclay, France;
(3) Malik Boudiaf, ÉTS Montreal, LIVIA, ILLS, Canada;
(4) Victor Storchan, Mozilla.ai, Paris, France;
(5) Myriam Tami, MICS, CentraleSupelec, Universite Paris-Saclay, France;
(6) Ismail Ben Ayed, ÉTS Montreal, LIVIA, ILLS, Canada;
(7) Celine Hudelot, MICS, CentraleSupelec, Universite Paris-Saclay, France;
(8) Pablo Piantanida, ILLS, MILA, CNRS, CentraleSupélec, Canada.
Table of Links
- Abstract & Introduction
- Related Work
- API-based Few-shot Learning
- An Enhanced Experimental Setting
- Experiments
- Conclusions
- Limitations, Acknowledgements, & References
- Appendix A: Proof of Proposition
- Appendix B: Additional Experimental Results
2 Related Work
2.1 Few-shot learning in NLP
Numerous studies have tackled the task of FSL in Natural Language Processing (NLP) by utilizing pre-trained language models (Devlin et al., 2018; Liu et al., 2019b; Radford et al., 2019; Yang et al., 2019). These methods can be classified into three major categories: prompt-based, parameter efficient tuning, and in-context learning.
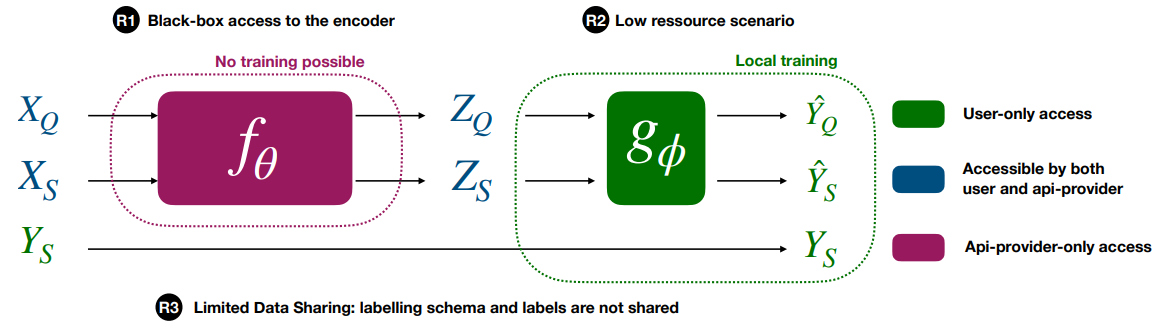
Prompt-based FSL: Prompt-based FSL involves the use of natural language prompts or templates to guide the model to perform a specific task (Ding et al., 2021; Liu et al., 2023). For example, the seminal work (Schick and Schütze, 2020a) proposed a model called PET, which uses a pre-defined set of prompts to perform various NLP tasks as text classification. They also impose a choice of a verbalizer which highly impacts the classification performances (Cui et al., 2022; Hu et al., 2021a). However, recent studies have questioned the benefits of prompt-based learning due to the high variability in performance caused by the choice of prompt (Liu et al., 2022). To address this issue, researchers have proposed prompt tuning which involves a few learnable parameters in addition to the prompt (Lester et al., 2021). Nevertheless, these approaches face limitations when learning from API: (i) encoder access for gradient computation is infeasible (as in R1), (ii) prompting requires to send data and label which raises privacy concerns (as in R3), and (iii) labeling new points is time-consuming (see in R3) and expensive due to the need to send all shots for each input token[1].
Parameter-efficient fine-tuning. These methods, such as adapters (Houlsby et al., 2019; Pfeiffer et al., 2020), keep most of the model’s parameters fixed during training and only update small feedforward networks that are inserted within the larger model architecture. A recent example is T-FEW (Liu et al., 2022), which adds learned vectors that rescale the network’s internal activations. Additionally, it requires a set of manually created prompts for each dataset making it hard to use in practice. Relying on parameter-efficient fine-tuning methods with an API is not possible due to the need to compute gradients of the encoder (as per R1) and the requirement to send both the labeling schema and the labels, which violates R3.
In Context Learning (ICL). In-context learning models are models that utilize input-to-output training examples as prompts to make predictions, without any parameter updates (Wei et al., 2022). These models, such as text-davinci, rely solely on the provided examples to generate predictions, without any additional training. However, a significant drawback of this approach is that the user must supply the input, label examples, and task description, which becomes prohibitively expensive when the number of classes or shots increases, is slow (Liu et al., 2022) (R2) and raises data privacy concerns (as highlighted in R3). Additionally, the inability to reuse text embeddings for new tasks or with new labels without querying the model’s API limits practicality and scalability, making reusable encoding unfeasible for in-context learning models [2].
or quite long stood as the de-facto paradigm for FSL ((Snell et al., 2017; Rusu et al., 2019; Sung et al., 2018b; Lee et al., 2019; Raghu et al., 2019; Sun et al., 2019a)). In meta-learning, the objective is to provide the model with the intrinsic ability to learn in a data-efficient manner. For instance, MAML ((Finn et al., 2017a; Antoniou et al., 2018)), arguably the most popular meta-learning method, tries to train a model such that it can be fine-tuned end-to-end using only a few supervised samples while retaining high generalization ability. Unlike the three previous lines of work, meta-learning methods operate by modifying the pre-training procedure and therefore assume access to both the training data and the model, which wholly breaks both R1 and R3.
2.2 Inductive vs transductive learning
Learning an inductive classifier on embeddings generated by an API-based model, as proposed by (Snell et al., 2017), is a common baseline for performing FSL. This approach is prevalent in NLP, where a parametric model is trained on data to infer general rules that are applied to label new, unseen data (known as inductive learning (Vapnik, 1999)). However, in FSL scenarios with limited labeled data, this approach can be highly ambiguous and lead to poor generalization.
Transduction offers an attractive alternative to inductive learning (Sain, 1996). Unlike inductive learning, which infers general rules from training data, transduction involves finding rules that work specifically for the unlabeled test data. By utilizing more data, such as unlabeled test instances, and aiming for a more localized rule rather than a general one, transductive learning has shown promise and practical benefits in computer vision (Boudiaf et al., 2020, 2021; Ziko et al., 2020). Transductive methods yield substantially better performance than their inductive counterparts by leveraging the statistics of the query set (Dhillon et al., 2019). However, this approach has not yet been explored in the context of textual data.
[1] The cost of API queries is determined by the number of input tokens that are transmitted.
[2] Furthermore, as the number of considered classes increases, the fixed size of the transformer limits the number of possible shots that can be fed to the model. Previous studies have often neglected this limitation by focusing on a few numbers of labels.