

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Pierre Colombo, Equall, Paris, France & MICS, CentraleSupelec, Universite Paris-Saclay, France;
(2) Victor Pellegrain, IRT SystemX Saclay, France & France & MICS, CentraleSupelec, Universite Paris-Saclay, France;
(3) Malik Boudiaf, ÉTS Montreal, LIVIA, ILLS, Canada;
(4) Victor Storchan, Mozilla.ai, Paris, France;
(5) Myriam Tami, MICS, CentraleSupelec, Universite Paris-Saclay, France;
(6) Ismail Ben Ayed, ÉTS Montreal, LIVIA, ILLS, Canada;
(7) Celine Hudelot, MICS, CentraleSupelec, Universite Paris-Saclay, France;
(8) Pablo Piantanida, ILLS, MILA, CNRS, CentraleSupélec, Canada.
Table of Links
- Abstract & Introduction
- Related Work
- API-based Few-shot Learning
- An Enhanced Experimental Setting
- Experiments
- Conclusions
- Limitations, Acknowledgements, & References
- Appendix A: Proof of Proposition
- Appendix B: Additional Experimental Results
5 Experiments
5.1 Case Study of text-davinci
In this experiment, we investigate the performance of text-davinci in both its language model and embedding-based model forms. We assess its classification capabilities using the aforementioned baseline and explore the language model’s performance when applied in an in-context learning (ICL) setup with prompting.
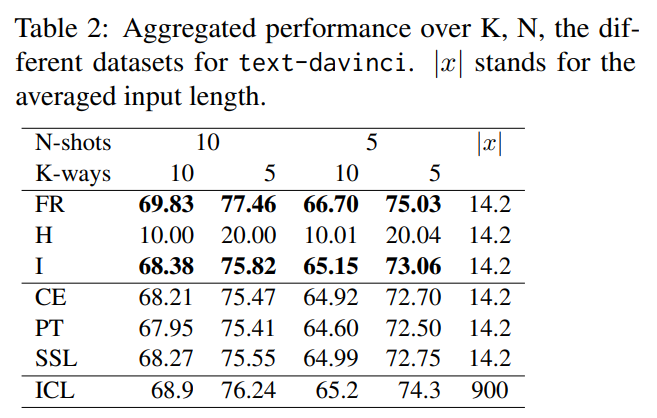
Takeaways. From Tab. 2, we observe that SSL performs comparably to CE, which is simpler to use and will be considered as the baseline in the next part of our study. Although ICL slightly outperforms CE, its implementation comes at a significant cost. In ICL, each class requires N shots, forcing the user to send a long input query with additional instructions. This query length becomes prohibitive as the number of classes increases, and on average, it is 58 times longer than using the embedding base API in our benchmark. The lengthy input and ICL approach make it time-consuming for generation (violating R1), require the user to provide labels (violating R2), and prevent the reuse of embeddings for future use (e.g., retrieval, clustering). Additionally, ICL is 60 times more expensive than CE. Thus, we will discard ICL for the subsequent part of this study.
5.2 Overall Results
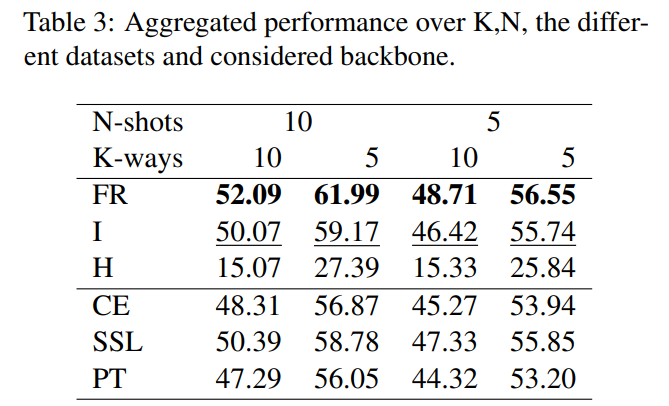
Global results: To evaluate the effectiveness of various few-shot methods, we conducted a comprehensive analysis of their classification performance across all datasets, all backbones, and all considered N-shots/K-ways scenarios. Results are reported in Tab. 3. An interesting observation is that transductive approaches I and FR outperform their inductive counterparts (CE and PT). Notably, we found that vanilla entropy minimization, which solely relies on H, consistently underperforms in all considered scenarios. Our analysis revealed that FR surpasses traditional fine-tuning based on cross-entropy by a margin of 3.7%.
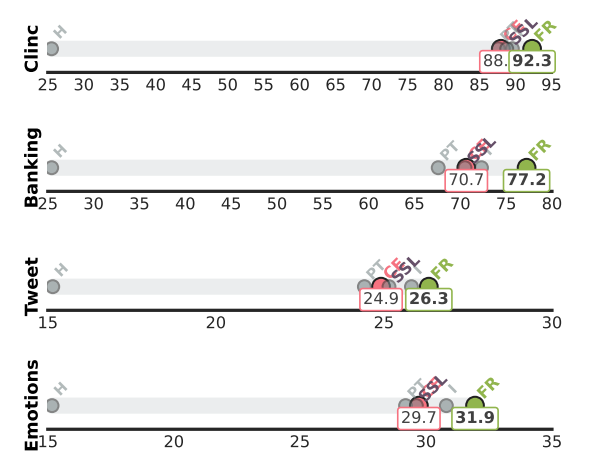
Mono-lingual experiment: In order to thoroughly analyze the performance of each method, we conducted a per-dataset study, beginning with a focus on the mono-lingual datasets. Fig. 2 reveals that the global trends observed in Tab. 3 remain consistent across datasets of varying difficulty levels. Notably, we observed consistent improvements achieved by transductive regularizers (such as I or FR) over CE. However, the relative improvement is highly dependent on the specific dataset being evaluated. Specifically, FR achieves +6.5% F1-score on Banking, but only a shy +1.5% on Tweet. A strong baseline generally suggests highly discriminative features for the task, and therefore a strong upside in leveraging additional unlabeled features, and vice versa. Therefore, we hypothesize that the potential gains to be obtained through transduction correlate with the baseline’s performance.[5]
5.3 Study Under Different Data-Regime
In this experiment, we investigated the performance of different loss functions under varying conditions of ’ways’ and ’shots’. As shown in Fig. 3, we observed that increasing the number of classes (’ways’) led to a decrease in F1 while increasing the number of examples per class (’shots’) led to an improvement in F1. This can be explained by the fact that having more data enables the classifier to better discern the characteristics of each class.
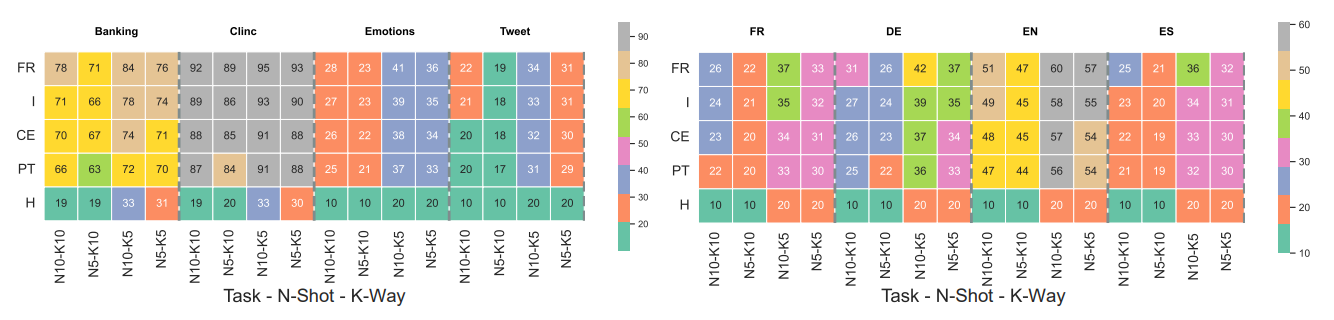
Interestingly, the relationship between the number of shots and classification F1 may not be the same for all classes or all loss functions. Fig. 3 shows that different loss functions (e.g. FR on banking) benefited greatly from adding a few shots, while others did not show as much improvement. However, this variability is dependent on the specific dataset and language being used, as different classes may have different levels of complexity and variability, and some may be inherently easier or harder to classify than others.
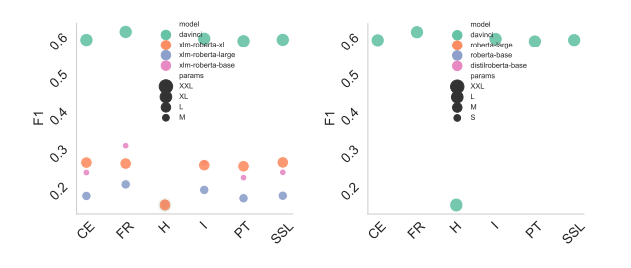
5.4 Ablation Study On Backbones
In this experiment, we examined how different loss functions perform when increasing the number of parameters in various models. The results, presented in Fig. 4, show the average performance across the experiments and are organized by the loss function. We observed an inverse scaling law for both the RoBERTa and XLM-RoBERTa family of models, where increasing the number of parameters led to a decrease in performance for the losses tested. However, within the same family, we observe that the superiority of FR remains consistent. An interesting finding from Fig. 4 is that the transductive regularization technique using FR outperforms other methods on text-davinci. This highlights the effectiveness of FR in improving the performance of the model and suggests that transductive regularization may be a promising approach for optimizing language models.
5.5 Practical Considerations
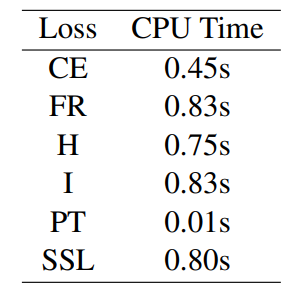
In this experiment, we adopt a practical standpoint and aim to evaluate the effectiveness of an API model, specifically text-davinci. In Tab. 4, we report the training speed of one episode on a MAC with CPU. Overall, we observed that the transductive loss is slower as it necessitates the computation of the loss on the query set, whereas PT is faster as it does not involve any optimization. Furthermore, we note that FR is comparable in speed to I. To provide a better understanding of these results, we can compare our method with existing approaches (in the light of R2). For instance, PET (Schick and Schütze, 2020a) entails a training time of 20 minutes on A100, while ADAPET (Tam et al., 2021) necessitates 10 minutes on the same hardware.
[5] Additional multilingual results (i.e., on es, de, fr) can be found on Sec. B.3. They exhibit the same behavior