This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Pierre Colombo, Equall, Paris, France & MICS, CentraleSupelec, Universite Paris-Saclay, France;
(2) Victor Pellegrain, IRT SystemX Saclay, France & France & MICS, CentraleSupelec, Universite Paris-Saclay, France;
(3) Malik Boudiaf, ÉTS Montreal, LIVIA, ILLS, Canada;
(4) Victor Storchan, Mozilla.ai, Paris, France;
(5) Myriam Tami, MICS, CentraleSupelec, Universite Paris-Saclay, France;
(6) Ismail Ben Ayed, ÉTS Montreal, LIVIA, ILLS, Canada;
(7) Celine Hudelot, MICS, CentraleSupelec, Universite Paris-Saclay, France;
(8) Pablo Piantanida, ILLS, MILA, CNRS, CentraleSupélec, Canada.
Table of Links
- Abstract & Introduction
- Related Work
- API-based Few-shot Learning
- An Enhanced Experimental Setting
- Experiments
- Conclusions
- Limitations, Acknowledgements, & References
- Appendix A: Proof of Proposition
- Appendix B: Additional Experimental Results
B Additional Experimental Results
B.1 Preliminary Classification Results
Preliminary Experiment. In our experiments, the backbone models are of utmost importance. Our objective in this preliminary experiment is to assess the efficacy of these models when fine-tuning only the model head across a variety of datasets. Through this evaluation, we aim to gain insight into their generalization abilities and any dataset-specific factors that may influence their performance. This information can be utilized to analyze the performance of different models in the few-shot scenario, as described in Sec. 5. We present the results of this experiment in Tab. 5, noting that all classes were considered, which differs from the episodic training approach detailed in Sec. 5.
B.2 A Dive Into text-davinci results
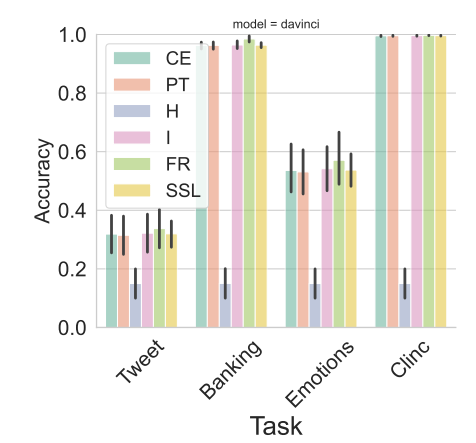
text-davinci appears to be the backbone providing the most informative a priori embeddings in Tab. 5 and could be considered as the prime model for API-based FSL, showcasing the current requirements in this area. It is thus a typical candidate for application uses that must meet the following criteria (R1) - (R3). Therefore, we put a special emphasis on its related results.
Fig. 6 (top) details the text-davinci results of the experiments conducted on the mono-lingual datasets. These plots highlight the consistency of the tendencies that emerged in Tab. 5, Tab. 3 and Fig. 2, namely: the superiority of transductive approaches (F R and I) over inductive ones (CE and P T), the underperformance of the entropic-minimization-based strategy (H), and the higher amount of information conveyed by text-davinci learned embeddings over other backbones, resulting in higher F1 scores on all datasets.
These phenomena still occur in the multi-lingual setting, as illustrated in Fig. 6 (bottom), stressing the superiority of transductive (and especially FR) over other approaches for presumably universal tasks, beyond English-centered ones, and without the need for using language-specific engineering as for prompting-based strategies.
Note that for both of these settings, the entropic-minimization-based strategy (H) seems to be capped at a 15% F1 score, thus with no improvement over other backbones embeddings, and independently of the dataset difficulty.
B.3 Multilingual Experiment
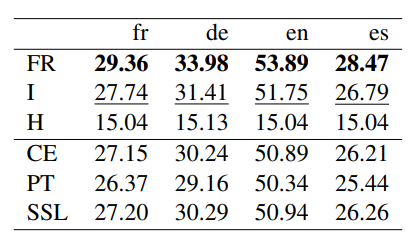
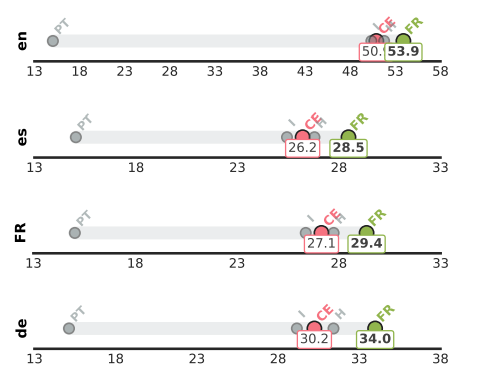
To provide an exhaustive analysis, we report the same experiment that is made in Sec. 5.2, for multi-lingual models on the Amazon dataset. While both Latin languages (French and Spanish) share close results, with an F1 gain of 2.8% for FR over CE, the results in the German and English language exhibit an F1 increased by almost 4%.
B.4 Importance of Model Backbones on Monolingual Experiment
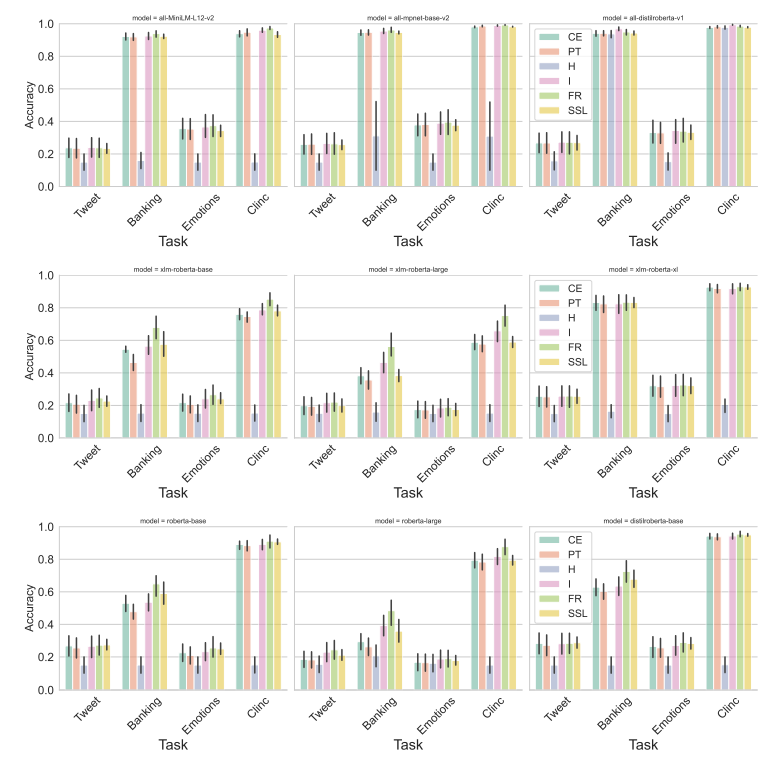
In this section, we report the results of our experiment aggregated per backbone. The goal is to understand how the different losses behave on the different backbones. The results are presented in Fig. 10. While the trends observed in the previous charts are retrieved for the majority of backbones, some of these models are exceptions. For example, while transductive methods perform generally better than inductive methods, the CE-based method seems to perform slightly better than I for XLM-RoBERTa-xl. Additionally, while FR is the most effective method for the majority of backbones, it is surpassed by I for the alldistilroberta-v1 model. Furthermore, the inverse-scaling-law details are found for the RoBERTa(B/L) and XLM-RoBERTa (B/L) models per dataset. In general, it is interesting to note that although model performance is constrained by dataset difficulty, the performance order of each method is consistent across all 4 datasets for each considered backbone.
B.4.1 Results Per Language
In this experiment, we report the performance of different losses on the Amazon dataset by averaging the results over the number of shots, ways, and model backbones. The results are presented in Tab. 6. Our observations indicate that the transductive regularization improves the results for all languages over the inductive baseline (i.e., CE), with a substantially higher gain for the German language. Additionally, we note that the observed improvements for FR are more consistent. This further demonstrates that the transductive loss can be useful in few-shot NLP. In the future, we would like to explore the application of transductive inference to other NLP tasks such as sequence generation (Pichler et al., 2022; Colombo et al., 2019, 2021d,b) and classification tasks (Chapuis et al., 2020; Colombo et al., 2022d,b; Himmi et al., 2023) as well as NLG evaluation (Colombo et al., 2021e, 2022c, 2021c,a,b) and Safe AI (Colombo et al., 2022a; Picot et al., 2022a,b; Darrin et al., 2022, 2023).